In this article, we’re going to talk about early architectural strategy for pre-idenfitied bottlenecks, how using a message queue can help, and run through an example application we built where this principle applied.
When we go about designing systems where there is a clear and expected performance bottleneck, how do we design the system to minimise it’s impact? Our dilemma is that whilst we don’t want to prematurely optimise, at the same time we would like to have a design that doesn’t massively stunt our ability to scale.
What is the answer to these competing priorities? In one word, isolation. In slightly more words, we try our best to ensure that the bottleneck is:
- Separated from the rest of the application.
- Is a very ‘pure’ component – e.g. doesn’t do anything that could be done elsewhere.
- Is stateless, if possible.
The example we’re going to look at is our new sentiment analysis platform that powers coinmarketmood. The basic premise of the system is that is reads tweets from twitter, uses rule based and machine learning methods to decide if a tweet expresses a positive or negative opinion about a certain subject, and then stores this in a database.
A naive approach might look like this:

We take data from twitter, analyse it, and write it to the database. There are a few issues with this. This is a system with a potentially very high throughput from twitter. The benefit of experience tells us that the slowest bits of such a system, slowest first, are likely to be:
- Sentiment Analysis in Python [Very heavy]
- Database Writes [Light]
- Tweet Retrieval [Light]
Since 2. and 3. are probably much of a muchness, we focus on point 1. We need to do quite a bit of complex work in Python, parsing grammatical structures, named entity recognition, part of speech tagging, and of course sentiment analysis.
If we rolled all these functions into one component, we are going to have to scale everything together, and that is a waste, because we know there is an imbalance between these tasks. For that reason, we want to isolate the heavy work, so that we can scale it independently. This is where a message queue comes in.
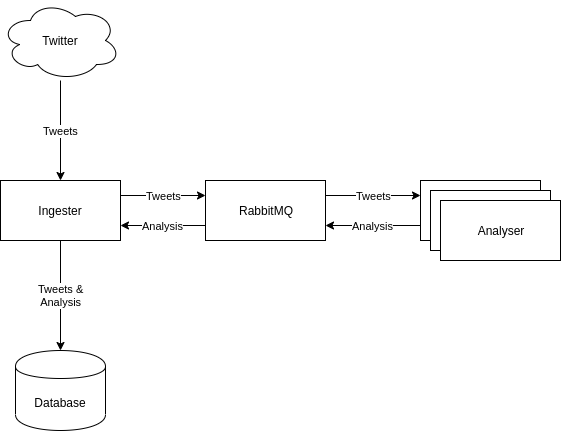
In this new design, the light work is on one side of the queue, and the heavy work on the other. We don’t expect the analyser to do the database writes either – we want to keep it pure. It writes back it’s analyses onto the message queue.
The end result of this is a very pure, single use component, which is stateless, and that we can scale independently. There are some useful side effects of this decoupling:
- The analysers can operate on a pull model, which means that if we are ingesting too much data from twitter, the analysers will not crash from oversupply, but messages will build up in RabbitMQ until we spin up another analsyer to service the demand.
- If either component goes down, the other component is unaffected.
In summary, a message queue is a useful way to decouple slow, bottleneck components from fast components, allowing you to address your bottleneck in isolation.
